|
TrialDriver |
|||
|
Developed by GCP-MB |
|||
 |
|
|
||||||||||||||||||||
|
Home — Data Management — EDC — SharePoint |
|||
|
TrialDriver Clinical Data Management |
|||
|
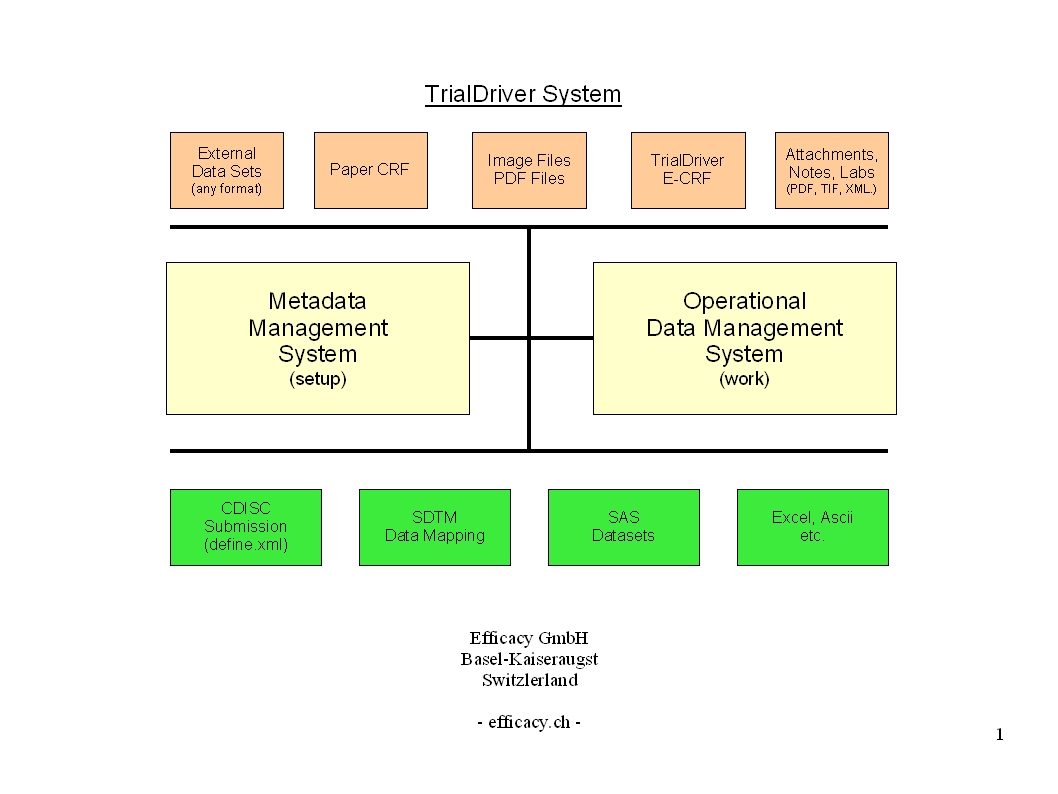
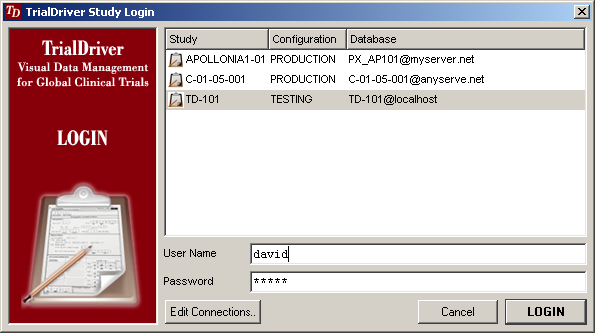
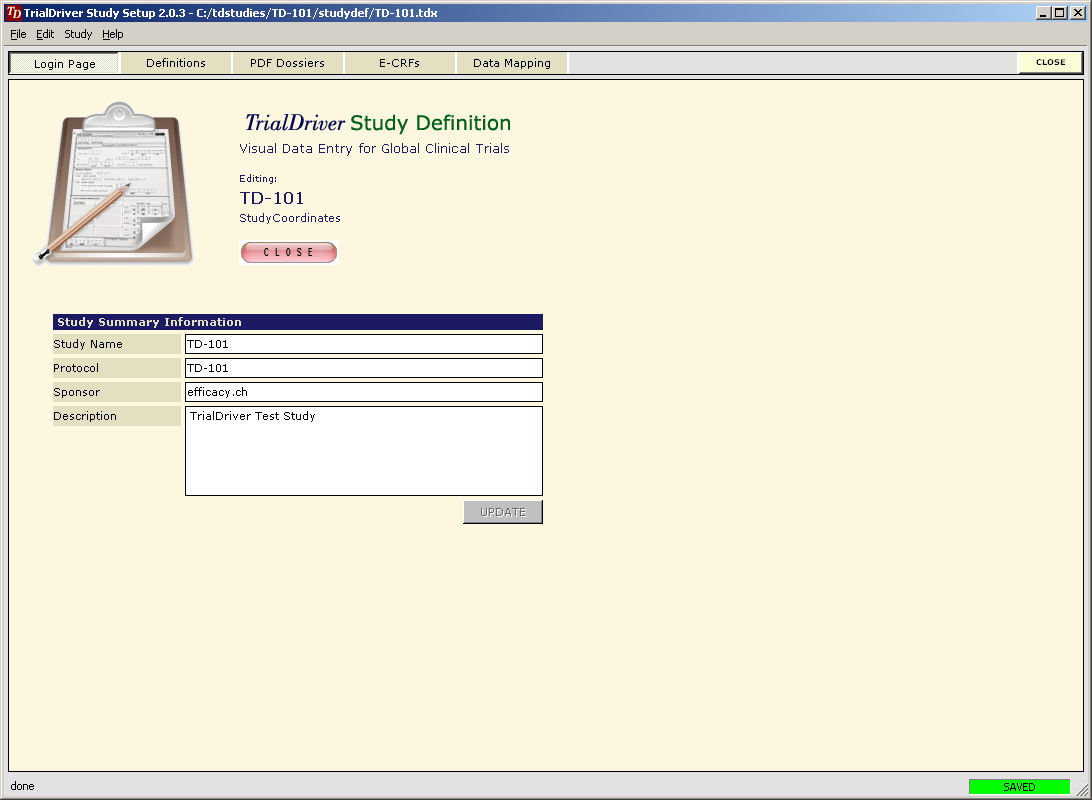
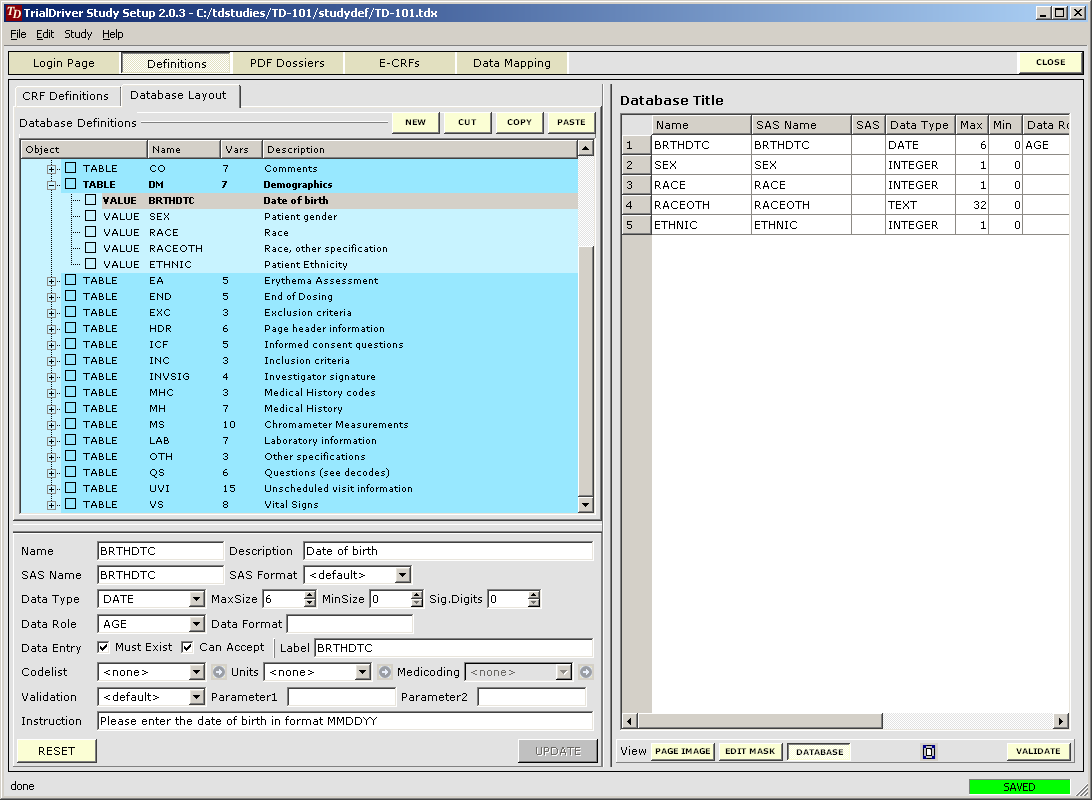
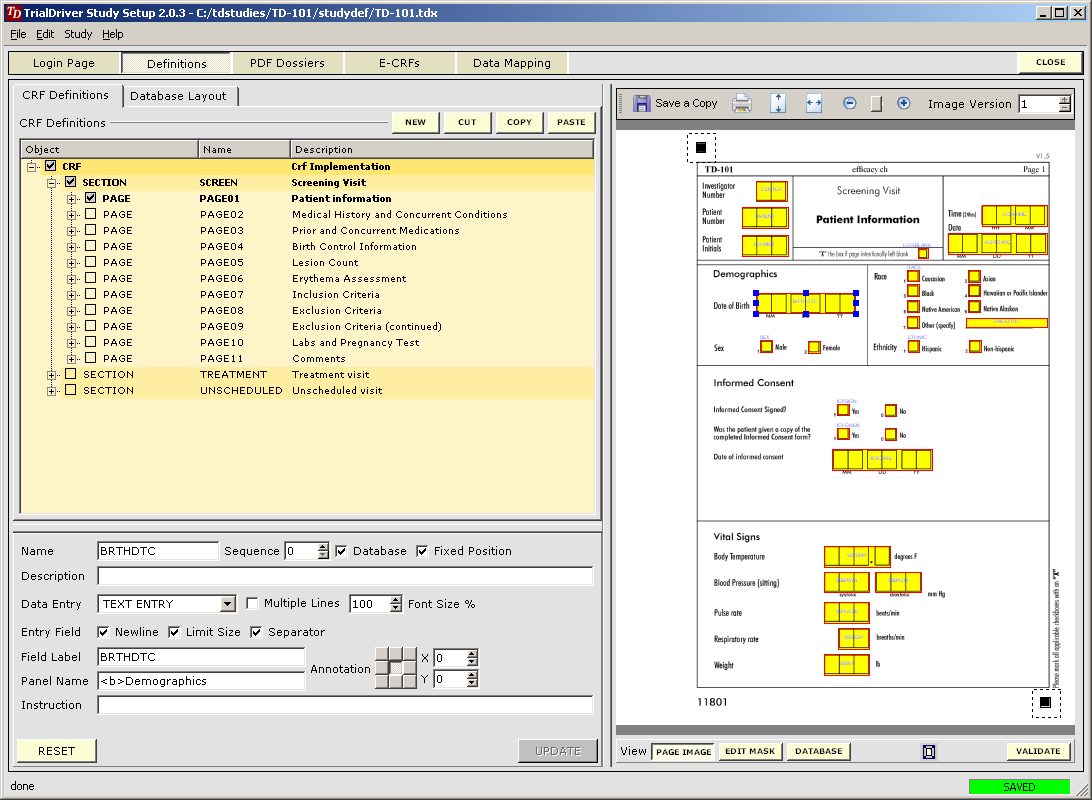
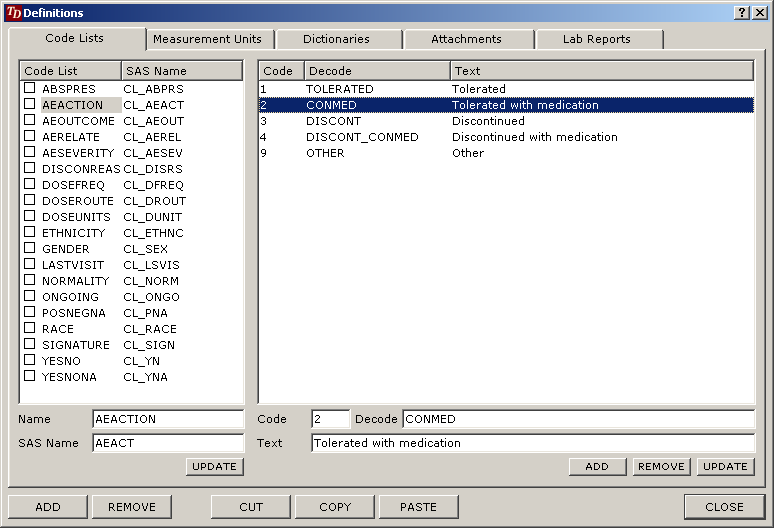
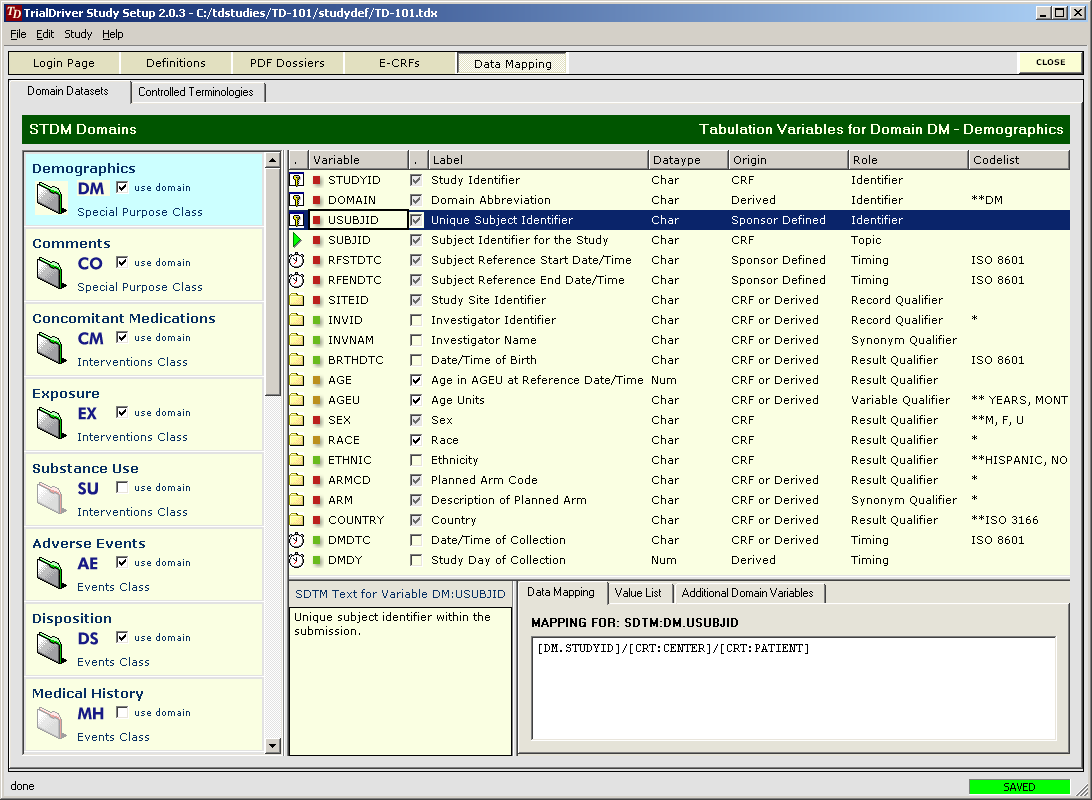
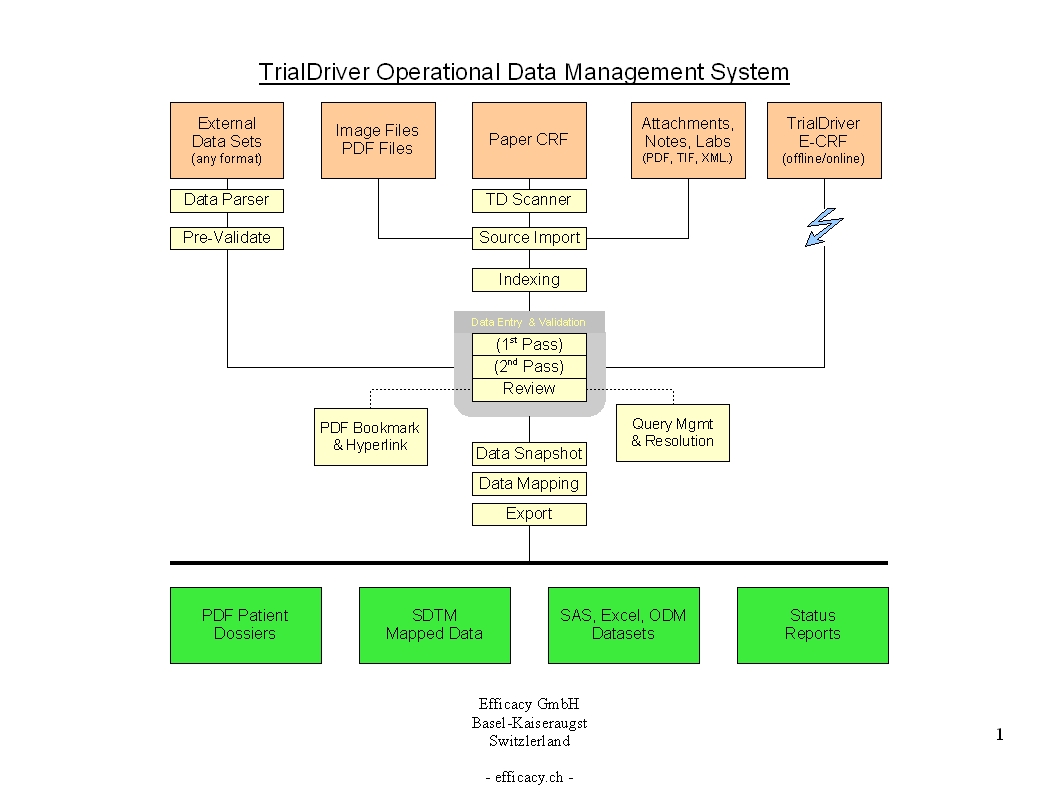
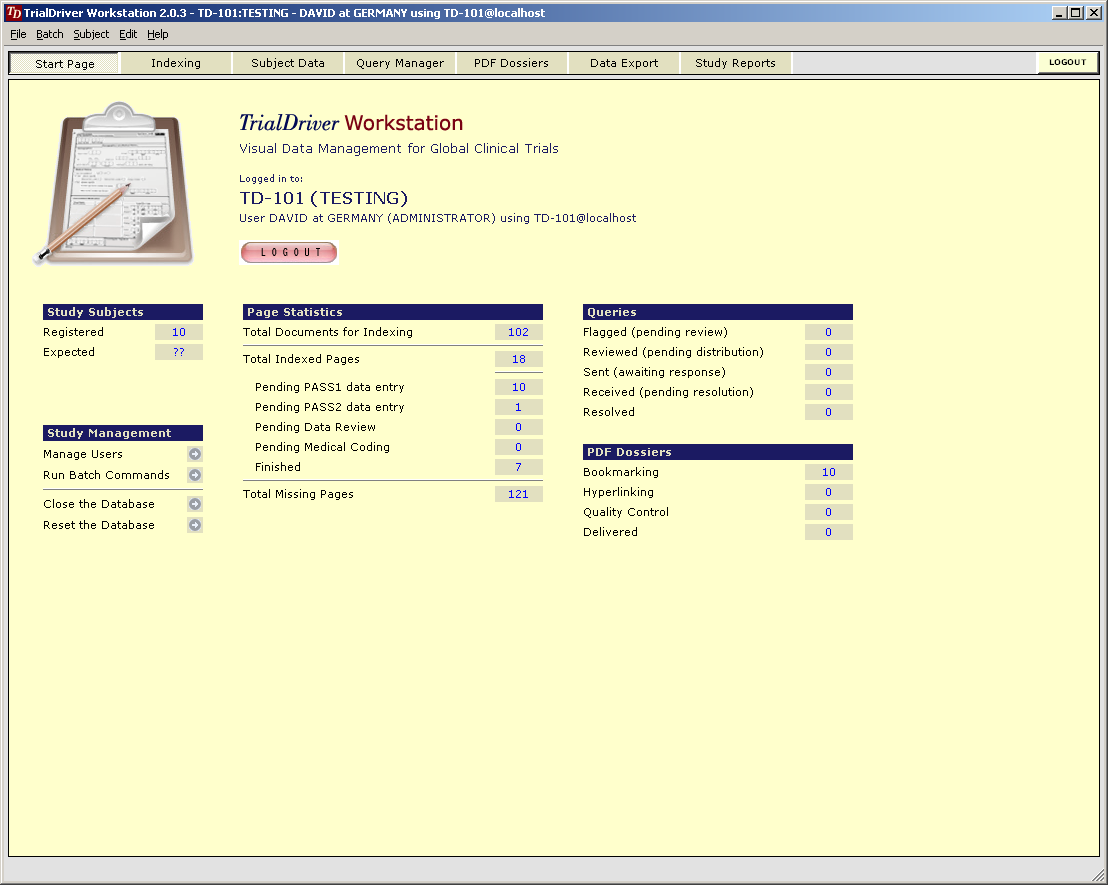
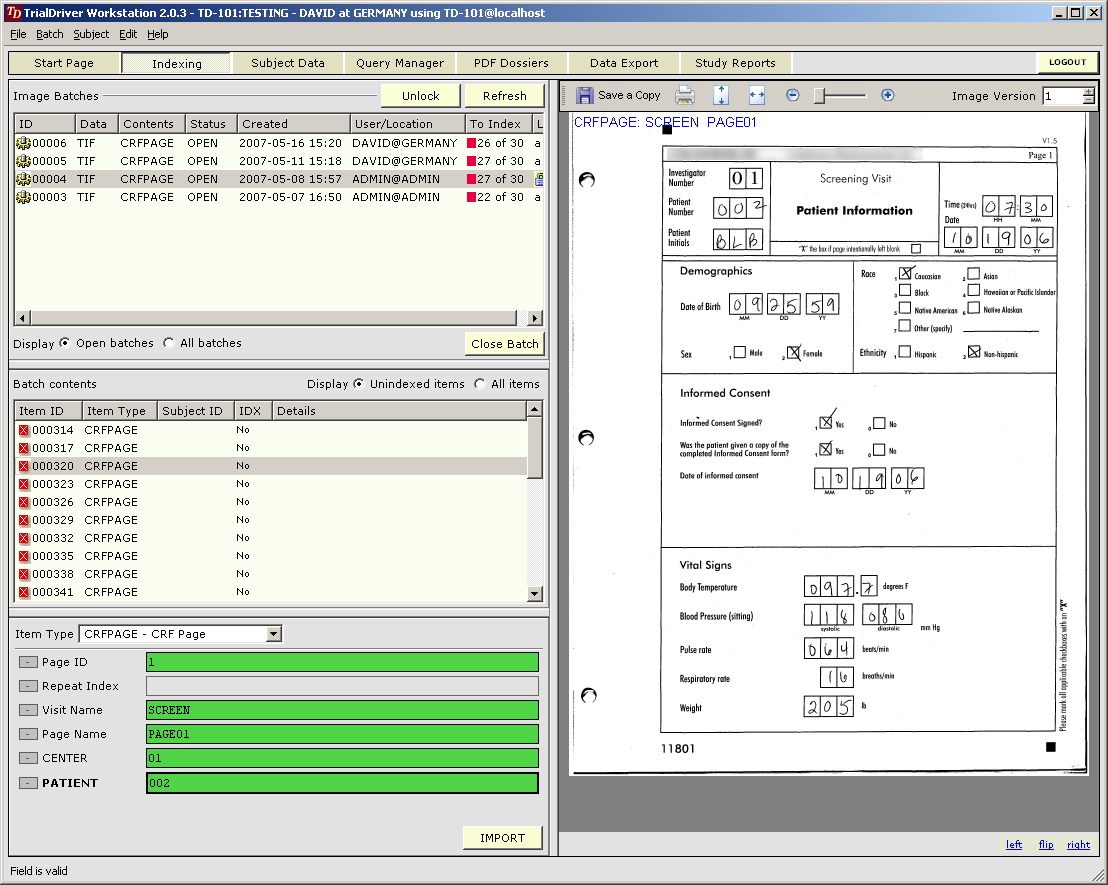
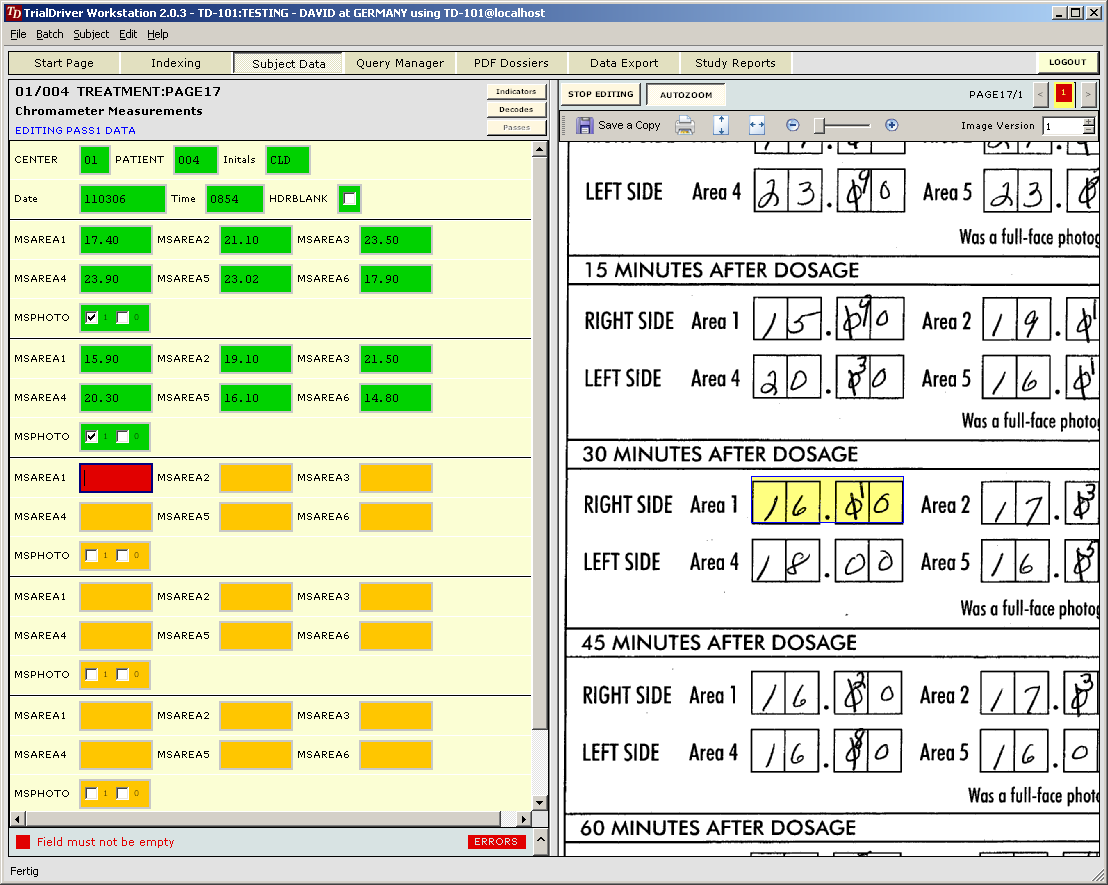
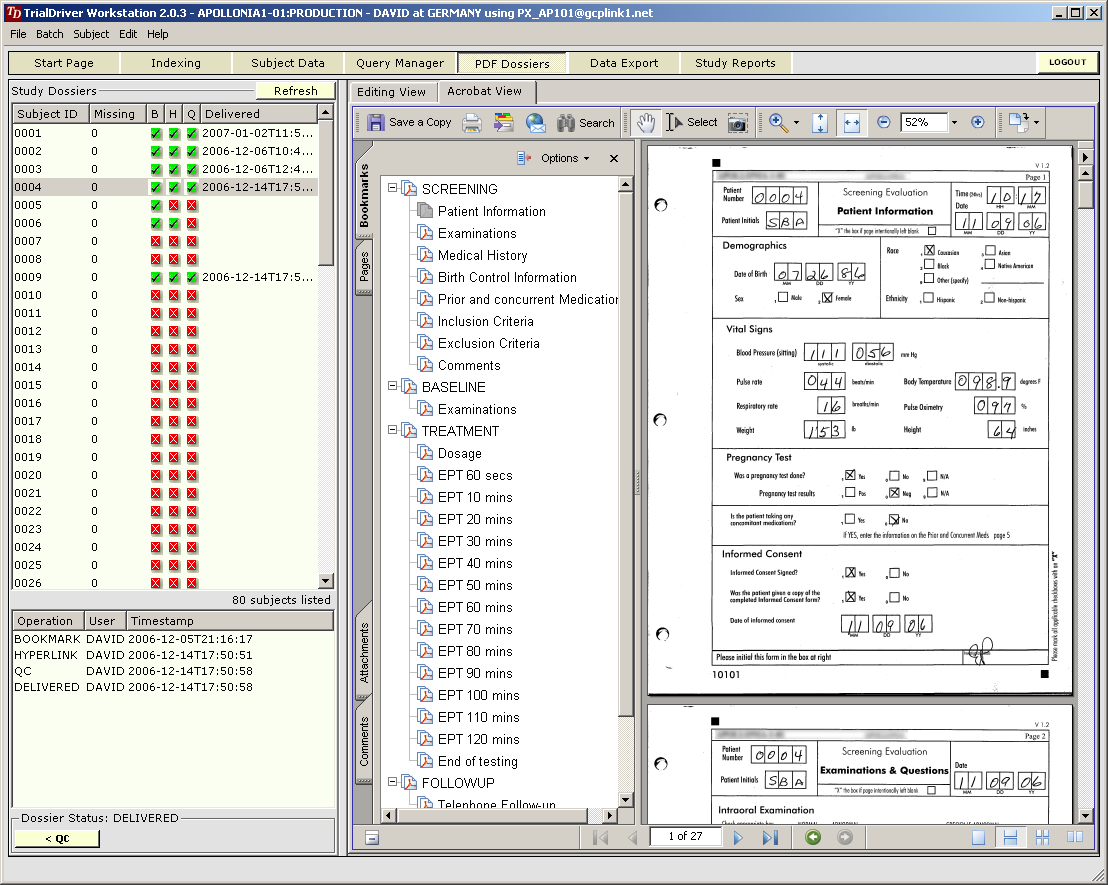
TrialDriver software has been designed to provide a complete image- and PDF-based Data Management solution for global clinical trials. It accepts a large range of inputs, including paper CRFs, image files and PDFs, electronic data from E-CRFs and/or legacy datasets. It provides comprehensive metadata creation and management facilities, including generation of operational databases, annotated CRFs, FDA submission documentation (define.xml) and SDTM data mapping specifications. Core of the TrialDriver software is a production quality, 21CFR11 compliant, Operational Data Management system, designed to collect high-quality, attributable and unambiguous data in a clearly defined workflow and with a minimum of effort. It integrates a subject indexing system, At the back end, data may be output in a variety of formats, including SAS load files, CDISC ODM data, Microsoft Excel format and others. Prior to output, data may be mapped to an SDTM structure using an integrated ETL engine and mapping designer. |
|
|
|
|
||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
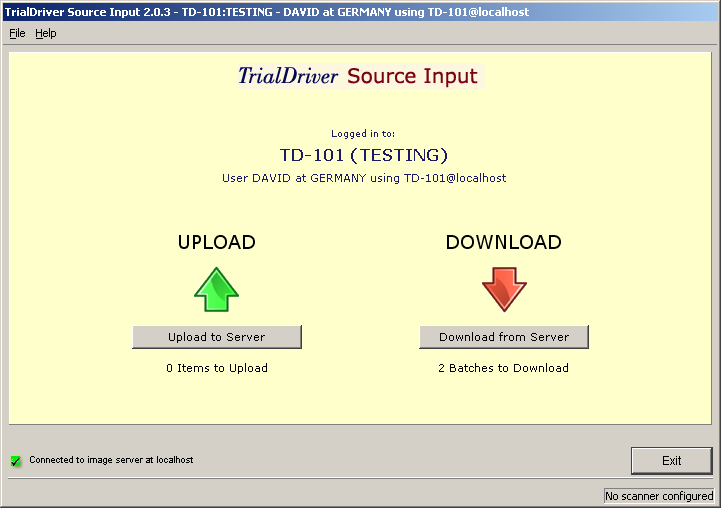
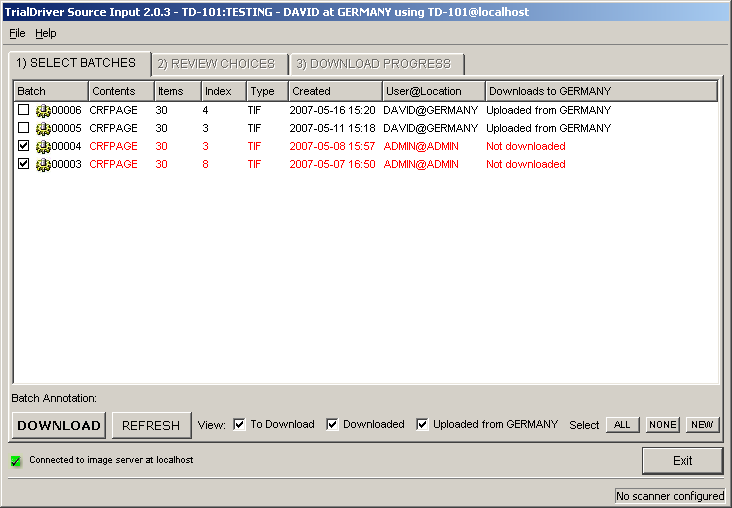
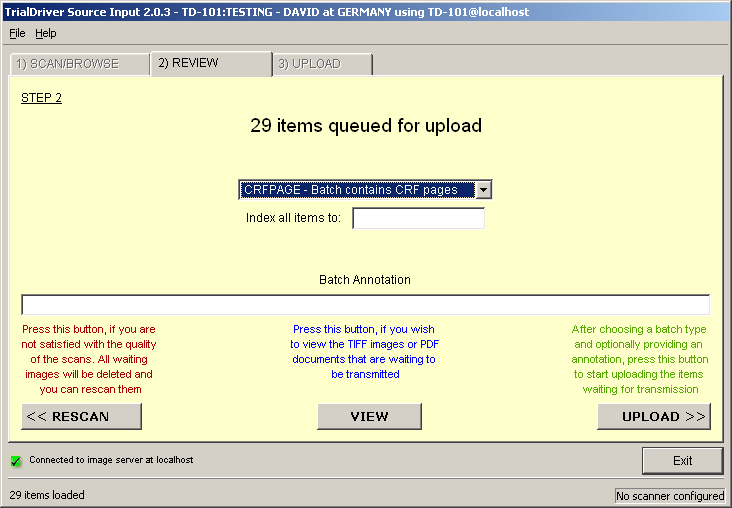
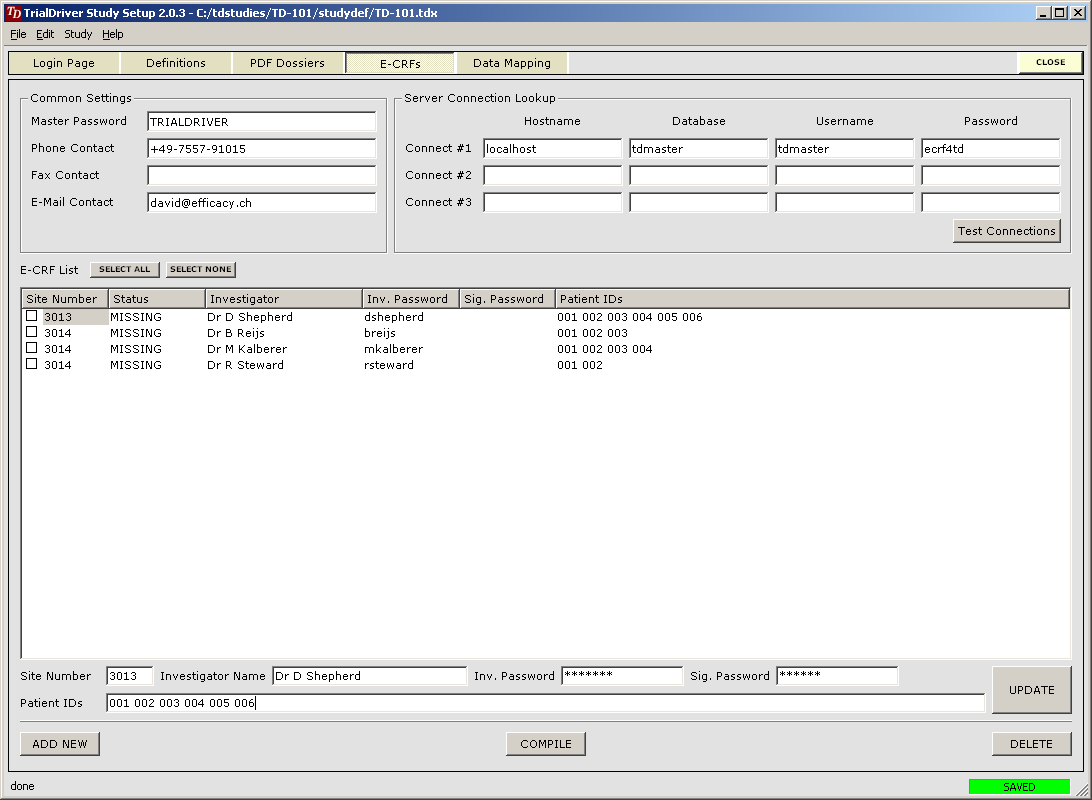
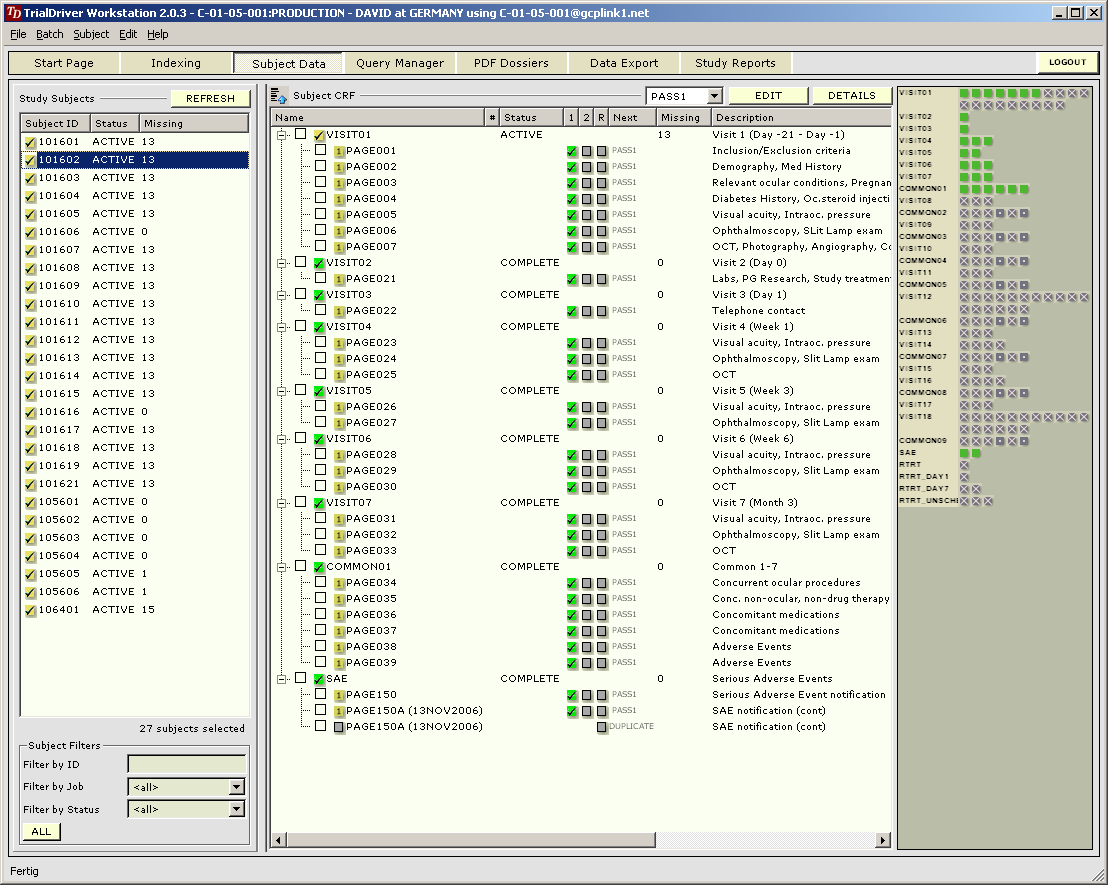
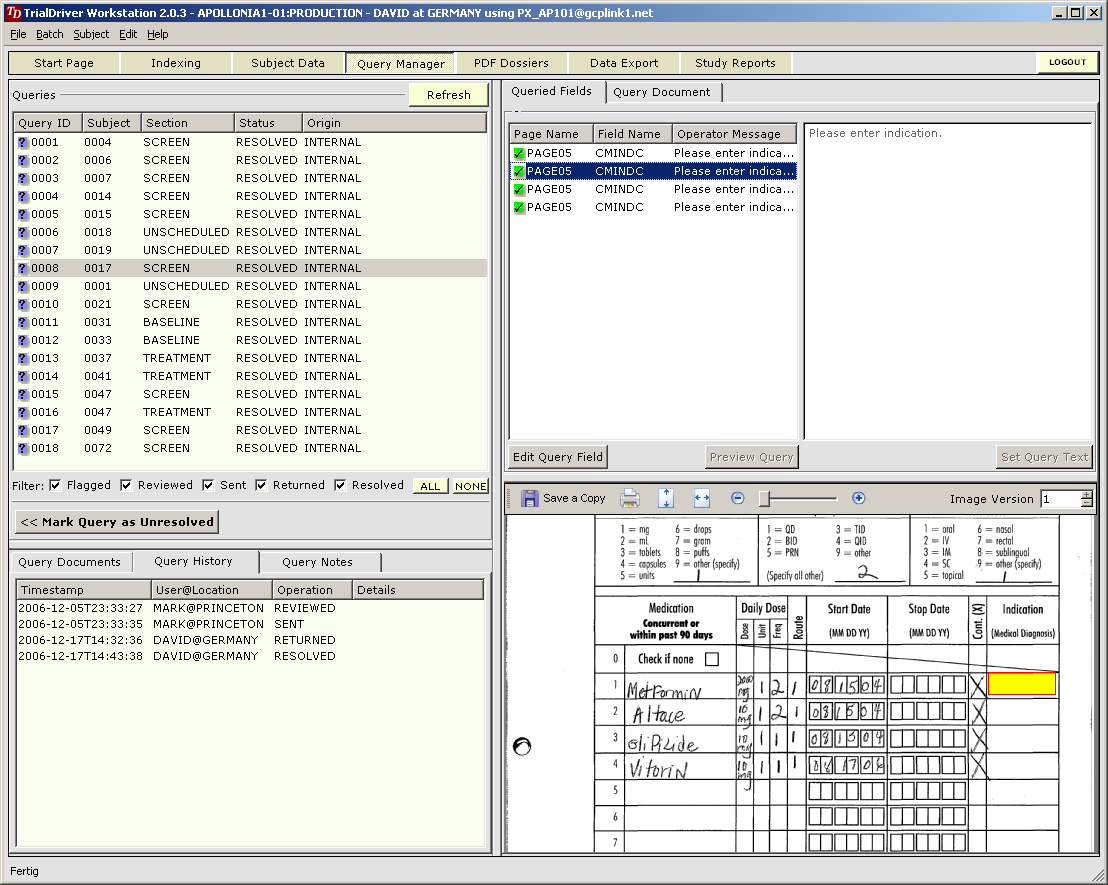
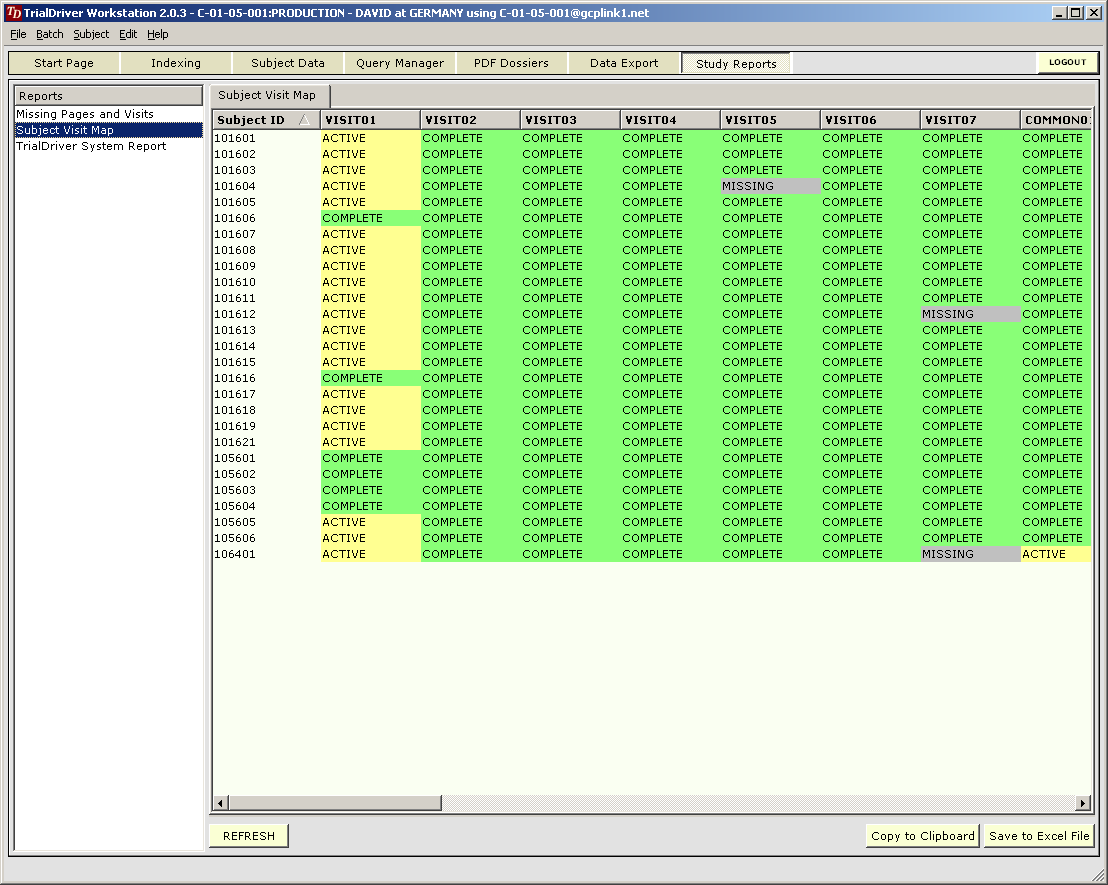
Core piece of the TrialDriver software is the work module (TDWORK), which provides a clear and simple workflow encompassing document-to-subject indexing, image-based, 2-pass data entry with discrepancy management (optionally single pass), a complete query lifecycle management system and comprehensive back-end data export, mapping and reporting options. It has been designed for 21CFR11 compliance and features a rich set of administrative functionality, including secure, role-based user access and a full Audit Trail. |
|
|
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
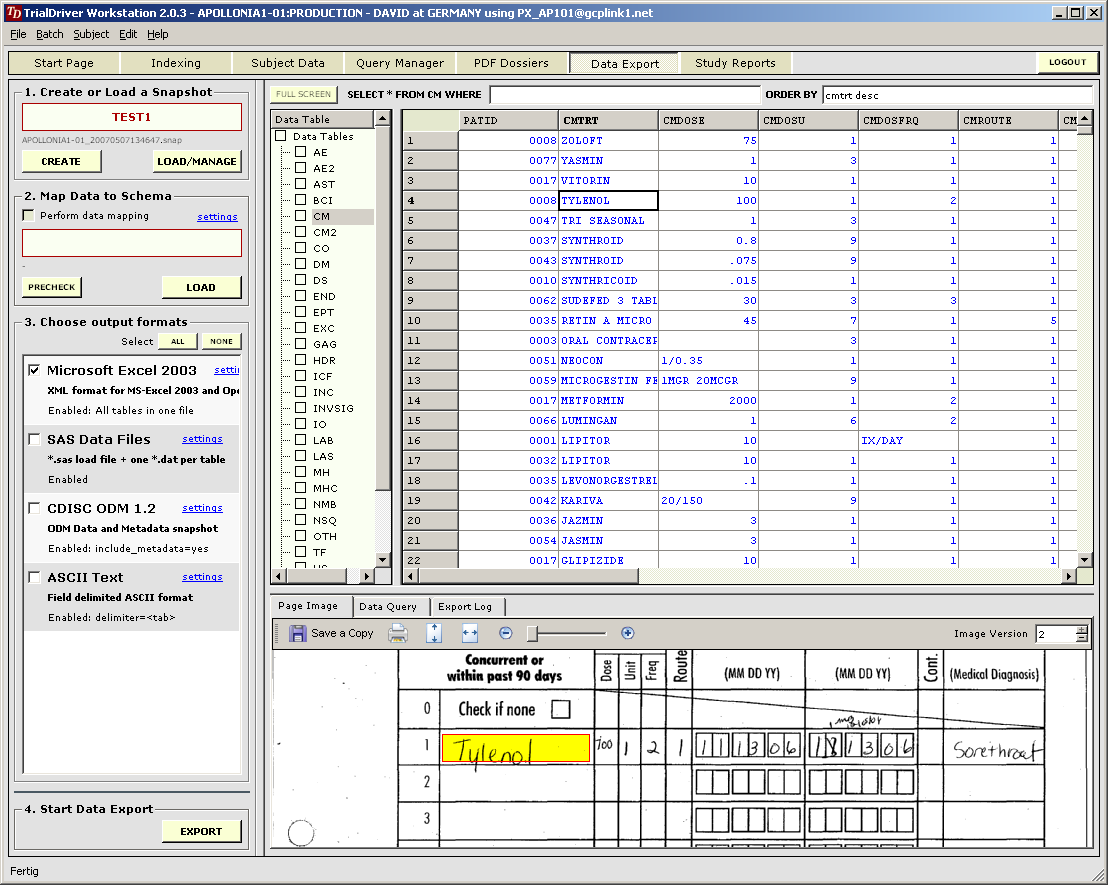
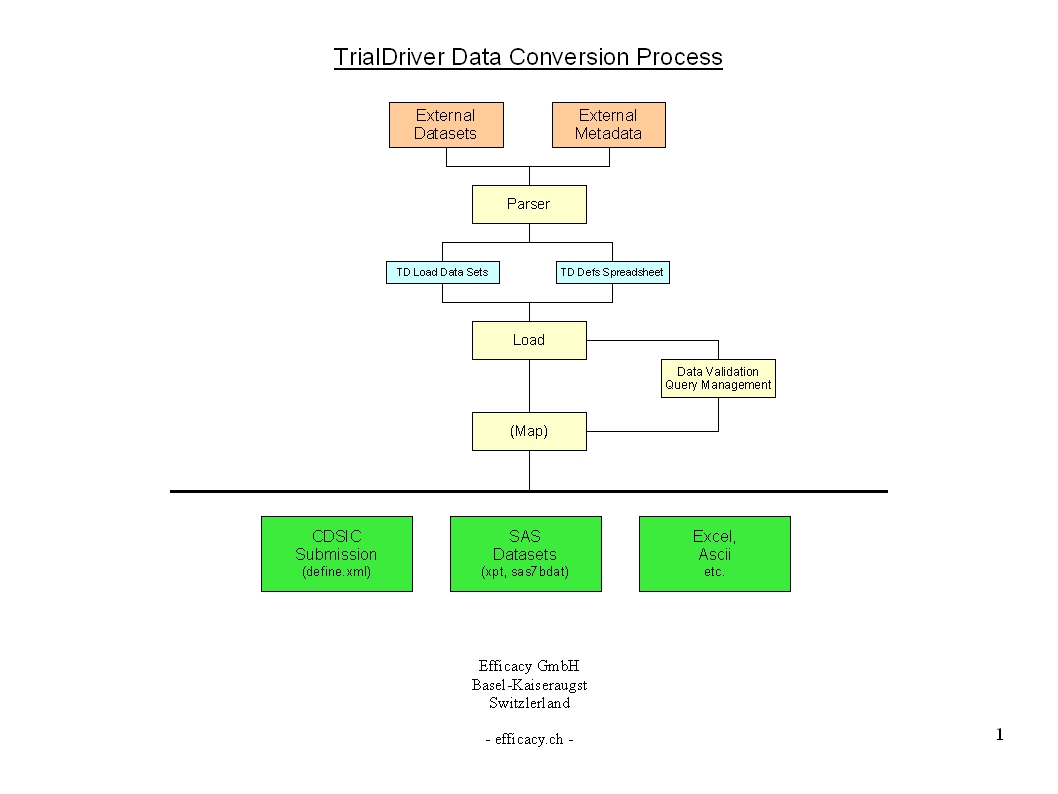
TrialDriver can import legacy data sets from any format and provide a clear and auditable path to convert these sets to a desired output format, such as SAS load files. To accomplish this, first a custom data parser is created for a given source format. Output from this parser is a set of TrialDriver load files and an Excel spreadsheet containing the automatically calculated study metadata - field lengths and data types for example. The study sponsor can now optionally add metadata information to the spreadsheet - the amount of metadata to be provided is dependent on the purpose to which the final data will be put. For a simple format conversion, no extra metadata is required. |
|
|
||||||||||||||||